Z nudów człowiek robi dziwne rzeczy. Jedną z nich jest parser dla plików CSS. Początkowo miał być to tokenizer który pozwoliłby na tworzenie różnego rodzaju narzędzi operujących na stylach CSS. Niestety po zapoznaniu się dokładnie ze strukturą CSS w wersji 2.1 odkładam ten plan na bliżej nie określoną przyszłość. Ale na pewno napisze, bo może być to ciekawe doświadczenie.
Po co mi ten skrypt ? Bo czasami jak otrzymam od kogoś kawałek szablonu ze skryptami. To wygląda to jak pole po bitwie lub niekończące się tasiemce. Często w pracy grafik przysyła nam szablony pocięte do tego CSS gdzie każda klasa szablonu jest napisana w jednej linii, a do tego bardzo długiej. Ja preferuje zupełnie odmienny styl.
Na początek musimy przeanalizować plik CSS. Wykorzystamy do tego proste wyrażenia regularne, które rozpoznają nam poszczególne części. Musimy rozpoznać 3 podstawowe rzeczy: Nazwę klasy wraz z jej ‘ciałem’, następnie z ów ciała musimy wyciągnąć atrybuty i ich wartości. Trzecią i ostatnią rzeczą są komentarze, które z mojego punktu widzenia są w ogóle niepotrzebne więc w tej wersji są po prostu usuwane.
/* wyrazenie regularne do wyszukiwania klas */
$patern_main = '~([\.|#]?[^{]*)[\s]*\{([^}]*)\}~i';
/* wyrazenie regularne do wyszukiwania atrybutow w klasach */
$patern_css = '~([^\:\;\s]+)\s*:\s*([^\;\s]+)~i';
/* wyrazenie regularne do wyszukania i usuniecia komentarzy */
$patern_comments = '~\/\*[^*]*\*+([^/*][^*]*\*+)*\/~i';
Cała reszta jest już prosta. W pierwszej kolejności usuwamy wszystkie znaki nowej linii oraz tabulatory, a następnie pozbywamy się wszystkich komentarzy. czyli:
$css = file_get_contents('/sciezka/do/pliku.css');
$css = str_replace(array("\n", "\r", "\t"), '', $css );
/* usuwanie komentarzy */
$css = preg_replace($patern_comments, '', $css);
Tak obrobiony styl będziemy teraz przeszukiwać, korzystając z wyrażeń regularnych.
/* wyszukiwanie klas */
preg_match_all($patern_main, $css, $match);
$css_array = array();
foreach (array_keys($match[0]) as $key) {
$css_match = array(); //czyscimy tablice w przypadku pustej klasy
$css_body = trim( $match[2][ $key ] );
if( $css_body != '' ) { //jesli definicja klasy jest pusta to ja opuszczamy
preg_match_all($patern_css, $css_body, $css_match);
$css_array[ trim( $match[1][ $key ] ) ] = array_combine($css_match[1], $css_match[2]);
} else {
$css_array[ trim( $match[1][ $key ] ) ] = array();
}
}
W ten sposób mamy już „rozłożony” styl CSS na czynniki pierwsze. Można by się pokusić oczywiście o sprawdzanie poprawności poszczególnych elementów i ich wartości. Ale sądzę że jest to raczej czysta formalność stworzyć słownik atrybutów oraz ich dopuszczalnych wartości.
Drugim pomysłem może być powiedzmy analiza i wyszukanie powtarzających się klas lub też wielokrotne powtarzanie tych samych atrybutów wraz z wartościami w różnych klasach. Ale podejrzewam, że będzie to materiał na inny wpis.
Teraz może poukładamy wszystkie klasy na dwa sposoby, „tasiemiec” oraz „drzewko”. Żeby wyjaśnić różnice pokaże przykładzie.
body { background-color: white; margin: 0px; padding: 0px; }
/*lub*/
body {
background-color: white;
margin: 0px;
padding: 0px;
}
Poniżej układamy CSS’a jeśli chcemy tasiemce zmienne $nl i $tab pozostawiamy puste lub też pozostawiamy tak jak teraz i mamy drzewka.
$nl = "\n";
$tab = "\t";
$string = '';
foreach( $css_array as $klasa => $body ) {
$string .= $klasa.' {'.$nl;
foreach( $body as $att => $value ) {
$string .= $tab."$att: $value;".$nl;
}
$string .= "}\n";
}
Oczywiście kod ma parę niedociągnięć. Nie obsługuje takich tagów jak import, charset ale może to kiedy indziej.
Czy komuś się to przyda nie wiem, jak w tytule był robiony w chwili wolnego czasu. Będzie chociaż troche ładnie poukładane.
Kod poskładany w całość:
<?php
$file = '/sciezka/do/pliku.css';
$css = file_get_contents($file);
$css = str_replace(array("\n", "\r", "\t"), '', $css );
/* wyrazenie regularne do wyszukiwania klas */
$patern_main = '~([\.|#]?[^{]*)[\s]*\{([^}]*)\}~i';
/* wyrazenie regularne do wyszukiwania atrybutow w klasach */
$patern_css = '~([^\:\;\s]+)\s*:\s*([^\;\s]+)~i';
/* wyrazenie regularne do wyszukania i usuniecia komentarzy */
$patern_comments = '~\/\*[^*]*\*+([^/*][^*]*\*+)*\/~i';
/* usuwanie komentarzy */
$css = preg_replace($patern_comments, '', $css);
/* wyszukiwanie klas */
preg_match_all($patern_main, $css, $match);
$css_array = array();
foreach (array_keys($match[0]) as $key) {
$css_match = array(); //czyscimy tablice w przypadku pustej klasy
$css_body = trim( $match[2][ $key ] );
if( $css_body != '' ) { //jesli definicja klasy jest pusta to ja opuszczamy
preg_match_all($patern_css, $css_body, $css_match);
$css_array[ trim( $match[1][ $key ] ) ] = array_combine($css_match[1], $css_match[2]);
} else {
$css_array[ trim( $match[1][ $key ] ) ] = array();
}
}
$nl = "\n";
$tab = "\t";
$string = '';
foreach( $css_array as $klasa => $body ) {
$string .= $klasa.' {'.$nl;
foreach( $body as $att => $value ) {
$string .= $tab."$att: $value;".$nl;
}
$string .= "}\n";
}
?>
 Kanał ATOM
Kanał ATOM







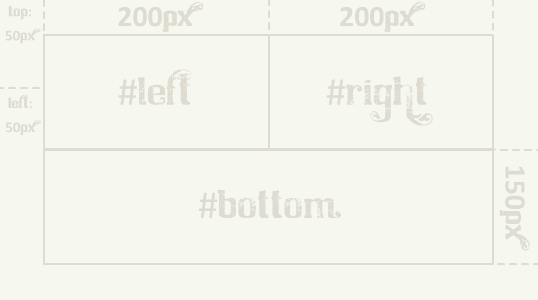
 Oczekiwany efekt.
Oczekiwany efekt.


 Różne typy komentarzy.
Różne typy komentarzy.